Over the past several months I have written several articles about AI as part of my own learning journey. Each time I dig deeper, I find new ways to explain how these systems work in a way that makes sense to people who are curious but not technical. This article continues that effort by covering what modern AI really is, where it came from, and how it learns. The goal is clarity without oversimplifying the ideas that make today’s models possible.

Artificial intelligence did not appear suddenly. It evolved from simple statistical tools into complex neural networks and eventually into transformer models that now power many of the tools we use today. What follows is a guided walkthrough of that evolution written for a novice audience who wants the story behind the technology.
Early Models
Before neural networks, AI relied on classical machine learning methods such as linear regression, logistic regression, decision trees, random forests, Support Vector Machines, Naive Bayes, and Hidden Markov Models. These models were very good at working with structured data such as spreadsheets or financial records. They made predictions, found rules, or classified inputs based on clear numeric and categorical patterns.
What they could not do was understand unstructured data such as images, audio, or natural language. They also required humans to manually design the features the model depended on, such as edge detectors, word counts, or specific engineered measurements. Nothing in the system could discover new patterns on its own. This limitation became the main bottleneck for early AI.
Reinforcement Learning
Reinforcement learning trains a model through trial and error. The agent interacts with an environment, takes actions, and receives rewards or penalties. Over time, the training algorithm adjusts the weights so reward-producing actions become more likely. The agent does not intentionally seek rewards. Its behavior is shaped by repeated training cycles.
This method is used in robotics, gaming systems, and for refining large language models using human feedback.
Neural Networks
Neural networks changed everything because they could learn features directly from raw data instead of relying on hand-crafted inputs. They are loosely inspired by the human brain, which contains billions of interconnected neurons that detect patterns at different levels. Artificial neural networks use much simpler mathematical neurons, but the idea is similar. Many connected units working together can learn increasingly complex relationships.
A typical network contains an input layer, several hidden layers, and an output layer. Each layer learns something different. Early layers detect simple patterns such as edges or color changes in images and short word relationships in language. Middle layers learn shapes, textures, and structured grammar. Deeper layers learn abstract concepts such as entire objects or the meaning of a sentence.
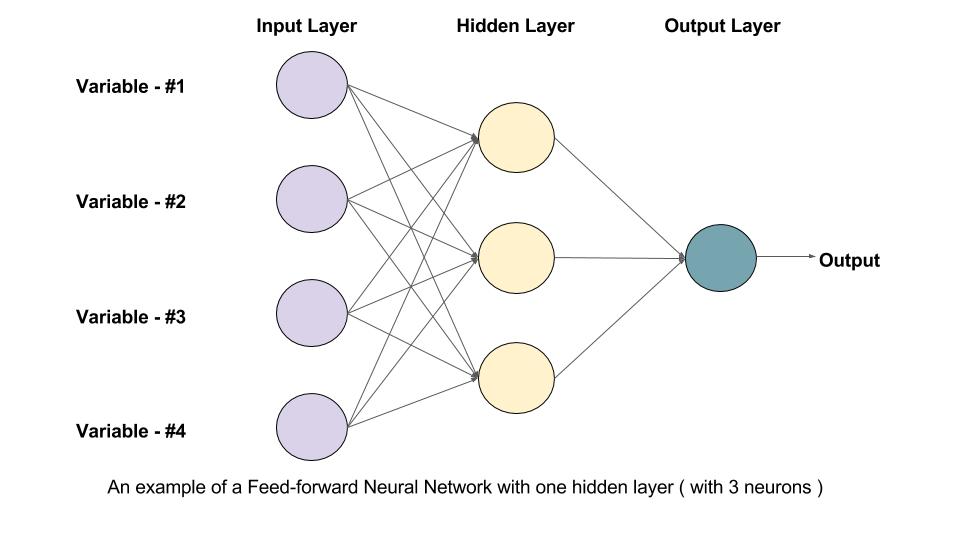
Modern neural networks can be very large. Older deep learning models often used tens of layers. Later breakthroughs expanded to hundreds. In today’s transformer-based systems, repeated transformer blocks function like layers, and these can scale into the thousands when the full architecture is counted. The depth gives the model enough capacity to capture subtle, high-level patterns that smaller networks cannot.
Layers do not always need to be strictly sequential. Many architectures use branches, parallel paths, or skip connections that allow information to bypass certain layers and rejoin later. These designs help stabilize training and allow the model to reuse useful information efficiently.
The network learns by adjusting its weights, which determine the strength of the connections between neurons. After training, these weights form the model’s internal knowledge. Transformers follow this same principle. They are still neural networks, simply built with a different internal structure centered around attention.
Types of Neural Networks
Different architectures evolved for different problems:
- Feedforward networks for general tasks
- Convolutional neural networks for images
- Recurrent networks and LSTMs for sequences
- Autoencoders for compression and reconstruction
- Graph neural networks for structured relationships
These formed the foundation of early deep learning.
Depth, Width, and Tradeoffs
A network’s depth refers to how many layers it has, while its width refers to how many neurons are in each layer. Increasing depth helps the model learn more abstract ideas. Increasing width gives it space to store more variations of those ideas.
There are important tradeoffs:
- larger networks require more data
- training becomes slower and requires more compute
- gains eventually level off
- very deep models can become unstable without careful design
Modern architectures balance size, performance, and efficiency.
Model Architecture and the Role of the Designer
A human designer creates the structure of the model before training begins. They choose:
- the number of layers
- the width of each layer
- the types of layers such as convolution, attention, or recurrent
- how layers connect, including normalization or skip connections
- training hyperparameters such as learning rate and batch size
The designer determines the structure. Training fills that structure with knowledge.
AI frameworks and libraries such as PyTorch, TensorFlow, and Keras make this process easier. They provide reusable building blocks for layers, optimizers, loss functions, and activation functions, which allows designers to focus on architecture and experiment with training strategies without writing every mathematical component from scratch.
Data, Compute, and the Cost of Training
Training a neural network can require significant data and compute power. Training happens over many cycles, called epochs or iterations. Each cycle processes the full dataset, measures how far off the model was, and adjusts the weights. Training consumes the most compute for several reasons:
- huge amounts of data must be processed repeatedly
- millions or billions of weights must be updated
- accuracy improves gradually
- multiple experiments are usually needed
Models do not produce certainties. They produce probabilities, not absolute answers. Designers monitor accuracy, loss, and confidence scores during training, then refine and retrain until the model reaches an acceptable performance level based on budget, time, and compute limitations.
Once training is complete, the model is saved as a checkpoint. This checkpoint is the version that gets deployed.
Inference vs Training
Using a trained model is called inference, and it is far less expensive than training. During inference the model does not update its weights. It simply applies what it already learned. This makes AI fast enough to use in real applications.
However, the knowledge inside a checkpoint is fixed. The model does not know anything newer than the data it was trained on. To update its internal knowledge, the model must be retrained or fine tuned with additional data.
Grounding and Extending a Fixed Model
Although a trained model’s knowledge is fixed, it can be extended through grounding. Grounding gives the model access to external information during inference. Approaches such as retrieval augmented generation let the model pull facts from updated sources. This improves accuracy and context but does not change the model’s internal weights. Long term improvement still requires retraining.
Overfitting
Overfitting occurs when a model memorizes training examples instead of learning general patterns. It performs well on data it has seen before but poorly on new data.
Overfitting looks different across learning types:
- in supervised learning, the model can memorize labels
- in unsupervised learning, it can learn noise instead of structure
- in reinforcement learning, the agent can exploit quirks of the training environment
Preventing overfitting requires enough data, regularization, and careful evaluation.
Transformers and Attention
The transformer architecture introduced in 2017 changed modern AI. It is still a neural network but built around attention, a method that allows the model to examine all parts of the input at once and determine which parts matter most.
Attention:
- identifies important relationships
- handles long sequences
- speeds up training through parallel processing
- reduces the need for oversized layers
- scales extremely well
Transformers now power nearly every major AI system including language models, image generators, audio systems, and multimodal applications.
Putting It All Together
Modern AI is the result of architecture, data, powerful compute, repeated training cycles, and innovations such as attention. Classical models provided structure. Neural networks introduced layered learning. Designers used frameworks and libraries to build balanced architectures. Reinforcement learning added trial and error. Transformers redefined how models understand context. Checkpoints preserve what the model learns, and grounding extends its usefulness until retraining updates its internal knowledge.
Key Terms
- Neural network: A layered system of artificial neurons.
- Layer: A group of neurons processing information at one level.
- Neuron: A mathematical unit that detects a pattern.
- Weight: A number controlling connectivity.
- Feature: A pattern the network learns automatically.
- Training: Adjusting weights to reduce error.
- Training rounds: Repeated passes through training data.
- Checkpoint: A saved version of a trained model.
- Inference: Using a trained model to generate outputs.
- Grounding: Adding external information at inference time.
- Overfitting: When a model memorizes instead of generalizing.
- Supervised learning: Training on labeled examples.
- Unsupervised learning: Training without labels.
- Reinforcement learning: Training through rewards and penalties.
- Transformer: A neural network architecture built around attention.
- Attention: A method that highlights the most relevant inputs.
- Compute: The processing power required for training and inference.