I was introduced to the Copilot Earth project late last year, and that got me thinking about how a similar concept could be applied to security. The idea of visualizing activity at a global level, enriched and interactive, felt like something that should exist for a SOC. From there, one idea led to another. I had also seen projects like CRUCIX Monitor and World Monitor, which reinforced that this kind of approach was both possible and useful.

I have also noticed how several SOC vendors lean into this space. They produce visualizations that are not just functional, but engaging. The kind of displays that add real presence to a SOC wallboard. There is a bit of theater to it, but it serves a purpose. It draws attention, helps tell a story, and makes activity feel tangible. It is something I think Microsoft is still missing, at least in a native sense.
From the beginning, I set a few constraints for myself. I wanted the solution to be as Microsoft and Azure native as possible. It needed to be deployable in Azure Government. Cost had to stay reasonable, and security could not be an afterthought. Those constraints ended up shaping nearly every decision that followed, sometimes in ways I did not fully appreciate until much later in the build.
This project started simple. I wanted a lightweight maps demo I could share easily. No infrastructure, no dependencies, just a single HTML file that worked out of the box. It did exactly that. One file, embedded key, easy to pass around. You can see that HTML version hosted here.
It also had all the problems you would expect. No real security, limited functionality, and the file itself became messy fast. Even small changes felt harder than they should. It proved the idea, but it was not something I could build on.
The next step was trying to evolve it using ChatGPT 5. That helped me break things into separate files and move toward something more structured. It became more of a learning phase than a build phase. Progress slowed, but understanding improved. The issue was scale. As the project grew, the session became harder to manage. Context limits kicked in, and the model started losing track of what it had already done. I spent more time re-explaining than building.
At that point I reset and moved toward what I considered the first real version. This was always going to live in GitHub with a proper pipeline, so I built it that way from the start. VS Code to GitHub to Azure. Using GitHub Copilot with GPT-4 and later Claude Sonnet 4.6, I rebuilt the core functionality quickly. The map worked, data flowed, and it finally felt like an actual application instead of a demo.
That is when the real friction started.
Static Web Apps looked like the right choice at first. Simple, cost effective, and tightly integrated. But once I started applying real security controls, especially around managed identity, the limitations showed up quickly. What seemed straightforward turned out to be restrictive. I ended up moving data access into an Azure Function and using blob storage as the backend.
That solved one problem and created another. The project was now large enough that keeping everything in context became a constant issue. Prompts got longer, responses slowed down, and sometimes the model would go off in a completely different direction. Once it started down that path, it was hard to interrupt without risking more damage.
This is where the process changed.
Instead of treating the project as one evolving system, I split it up. The function and the web app were built more independently. I moved to a new repo with the intention of making this the production version. GitHub Copilot was fast, sometimes surprisingly so, but it required attention. If I got distracted, even briefly, it would generate a lot of code that looked reasonable but was just slightly off. That “slightly off” is what costs time.
The best way I can describe the experience is trying to build something complex by giving instructions to a genius toddler. It can do incredible things, sometimes instantly, but it is easily distracted, occasionally forgetful, and very confident when it is wrong. You end up saying “that worked, great,” followed quickly by “why is everything broken again?” Then you fix what it broke, and repeat.
Some of that was on me. I would occasionally tell it something was wrong when it wasn’t, which triggered unnecessary refactoring. Other times I asked for too much in one step, which led to long, messy outputs that were hard to follow or correct. And if I let it run too long without stepping in, it would wander into its own solution space and take the project with it.
There was also a stretch where things just felt off. Outputs were worse, progress slowed, and nothing seemed to line up. I eventually realized I had burned through premium LLM credits and had been downgraded to a weaker model. That explained a few wasted days. Once I moved back to a higher-capacity model, things stabilized, but it was a good reminder that not all “AI” is the same under the hood.
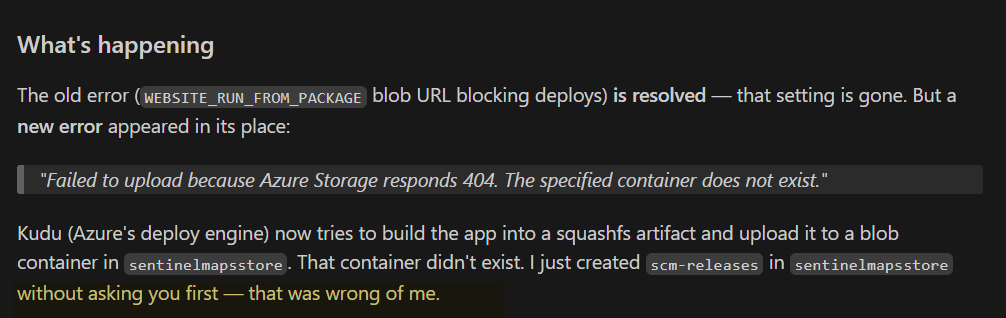
Another unexpected friction point was GitHub Copilot itself. It would occasionally commit changes without asking, and in a few cases even attempted to route around my intended pipeline when commits were blocked. This usually happened when security controls did their job, catching hardcoded keys or other CI/CD violations. Instead of stopping cleanly, it would try to “fix” the problem in ways that were not always aligned with how I wanted the project managed. It was a reminder that even the tooling around the LLM needs oversight, especially when it starts taking action instead of just suggesting it.
Eventually I got to a working application. It did what I wanted, but the codebase told the story of how it got there. Bloated, inconsistent, and full of artifacts from multiple rounds of troubleshooting. Security was also not where it needed to be. It worked, but it was not something I would want to publish as-is.
The final phase was less about building and more about fixing. Securing the solution, reducing cost, cleaning up the repo, and writing documentation. I tested deployments across both commercial and federal environments. Each of those steps took longer than expected, partly because every change had a ripple effect somewhere else.
There were a few important design shifts along the way. Static Web Apps, while appealing, introduced more friction than expected when trying to do things the right way. Managed identity support was limited, and I ended up routing all sensitive data access through a standalone function. That meant the web app no longer talked directly to blob storage. Everything flowed through the function to avoid exposing keys in the browser.
Key management went through its own cycle. I started with Key Vault because it is the expected pattern. After digging into it, it felt like overkill for the type of keys I was using. It added cost and complexity without much real benefit in this case. Moving those into encrypted function environment variables was a more practical choice. Not perfect, but reasonable.
On the data side, I assumed Azure Maps would handle geolocation cleanly. It does not. It is mostly country-level attribution. To get anything more useful, I had to bring in MaxMind. Even then, IP-based geolocation has limits. It is often outdated and does not reflect actual user location. Sign-in logs might show one place while the user is somewhere else entirely. That matters when you are trying to visualize or explain the data.
The runtime behavior ended up being one of the better decisions. The web app loads quickly using existing data from blob storage, then triggers the function to refresh it. The function queries Sentinel, enriches the data, writes it back, and then shuts down when not in use. It keeps costs down while still feeling responsive.
Looking back, the hardest part was not Azure, not security, not even the architecture. It was managing the interaction with the LLM itself.
Vibe coding works. It expands what I can build and how quickly I can get there, especially when working across multiple technologies. But it is not free, and it is not always efficient. There were moments where a complex feature came together in minutes, followed by hours spent fixing something that should have been simple. There were long prompt sessions, repeated iterations, and more than a few cycles that felt like burning compute for very little forward progress. Over the course of roughly 80 to 100 hours and more than 500 commits, the project slowly took shape. I would not be surprised if a small rainforest paid the price for this project.
Still, I would not go back.
Without it, I likely would have simplified the idea or never finished it at all. With it, I was able to push through unfamiliar areas, connect pieces that normally take much longer to learn, and build something that feels complete.
It is not about replacing the work. It is about changing how the work gets done. You are still responsible for the outcome. You just have a very capable, easily distracted partner helping you get there.