Security teams are starting to use and pay closer attention to tools like MCP servers, AI agents, GitHub Copilot, VS Code integrations, and other AI-assisted operational tooling. As organizations become more familiar with these tools, it naturally raises questions around the privacy and security implications of connecting them to enterprise systems.
The real issue is not MCP or similar services by themselves.
The larger concern is that modern administrators can now retrieve enterprise telemetry through APIs, agents, copilots, automation frameworks, and interactive tooling, then immediately hand that information to another system for processing. That “other system” might be a public LLM, a local model, a third-party orchestration platform, a local file, or another external datastore entirely. At that point, this becomes less about AI itself and more about data governance, operational visibility, and potential exfiltration.
For example, most employees already understand that copying sensitive internal information directly into the chat interface of a public LLM for summarization or analysis would generally be considered a privacy or data handling violation. If an administrator copied incident data, authentication logs, customer records, or internal investigation details into a public AI chatbot, most security teams would immediately recognize the concern. Yet, when we use APIs, MCP servers, and AI-assisted tooling, that same message can sometimes get lost because the interaction feels more operationally legitimate and less like traditional data sharing.
This is also not an attack scenario in the traditional sense. In the situations discussed here, the identities involved are fully authorized to perform the actions they are performing.
That is what makes this problem different.
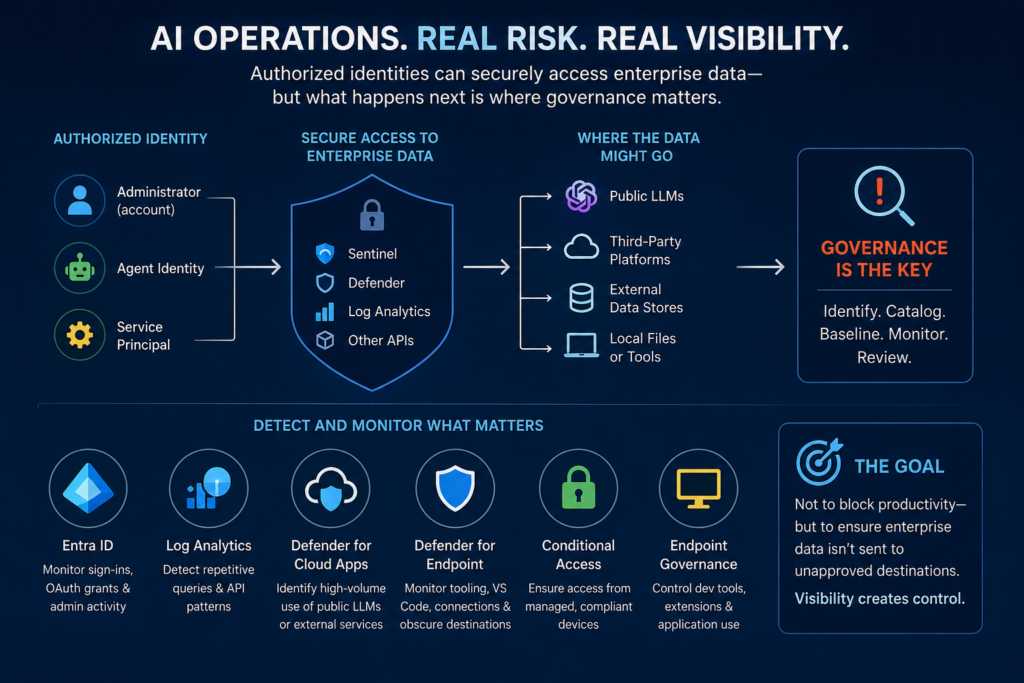
An administrator, service principal, or agent identity may legitimately have permission to query Sentinel, retrieve incidents, access Defender telemetry, or read Log Analytics data. The concern is not whether the identity was authorized to retrieve the information. The concern is what happens to that information after retrieval.
In many cases, the user may not even realize they are creating a governance concern. The workflow itself may be highly useful and operationally beneficial. The problem is that enterprise telemetry may ultimately be processed, stored, summarized, or transmitted to systems that were never formally approved to handle that information.
And importantly, none of this is unique to Microsoft technologies. I am using Microsoft services and identities as examples because that is the ecosystem I work with most often, but the same concerns exist across cloud providers and enterprise platforms in general.
The shift from APIs to interactive AI operations
For years, enterprise automation largely revolved around APIs and key-based authentication methods. In Microsoft environments, that typically meant app registrations, API permissions, client secrets, certificates, and application-based authentication flows.
Historically, this type of integration work was still mostly limited to developers, engineers, and automation specialists. Most enterprise administrators were not building custom API integrations themselves.
That is changing rapidly.
The combination of AI-assisted development, vibe coding, MCP frameworks, copilots, and agentic tooling is dramatically lowering the barrier to entry for automation. Administrators who may never have previously built an integration can now generate scripts, workflows, and orchestration logic in minutes.
In many cases, they are leveraging LLMs to generate code they do not fully understand because they are not traditional developers. That increases the likelihood of building workflows that function operationally while still making poor decisions from a privacy or governance perspective.
Traditional API integrations also created cleaner monitoring boundaries. Service principal activity exists separately from normal user activity, making it easier to baseline and monitor. Authentication events generated by an application identity are not mixed together with normal workstation activity like email, Teams, or web browsing.
Modern AI tooling changes that equation significantly because it expands these capabilities far beyond traditional developers and automation engineers.
MCP, delegated authentication, and agent identities
One of the more interesting shifts with MCP servers and newer AI frameworks is the increased use of delegated user authentication through standard user sign-on flows, OAuth grants, and interactive identity-based authentication rather than isolated application identities alone.
That is not necessarily a bad thing.
When an administrator authenticates interactively using Entra, organizations can still enforce multi-factor authentication, Conditional Access, compliant device requirements, and identity risk policies. A client secret cannot participate in Conditional Access. A delegated user session can.
Microsoft is also beginning to move toward concepts like agent identities, where autonomous systems can operate with identities more closely aligned to user-style governance controls rather than traditional application secrets alone. This allows organizations to move away from long-lived keys while still applying Conditional Access policies and stronger operational attribution to autonomous workflows.
The issue, however, is not the authentication process itself. The issue is what the authorized identity chooses to do with the data after retrieval.
An administrator, delegated user session, service principal, or agent identity may successfully authenticate through legitimate enterprise controls, retrieve authorized enterprise telemetry, and then knowingly or unknowingly process that information through systems that would not meet enterprise privacy or governance expectations.
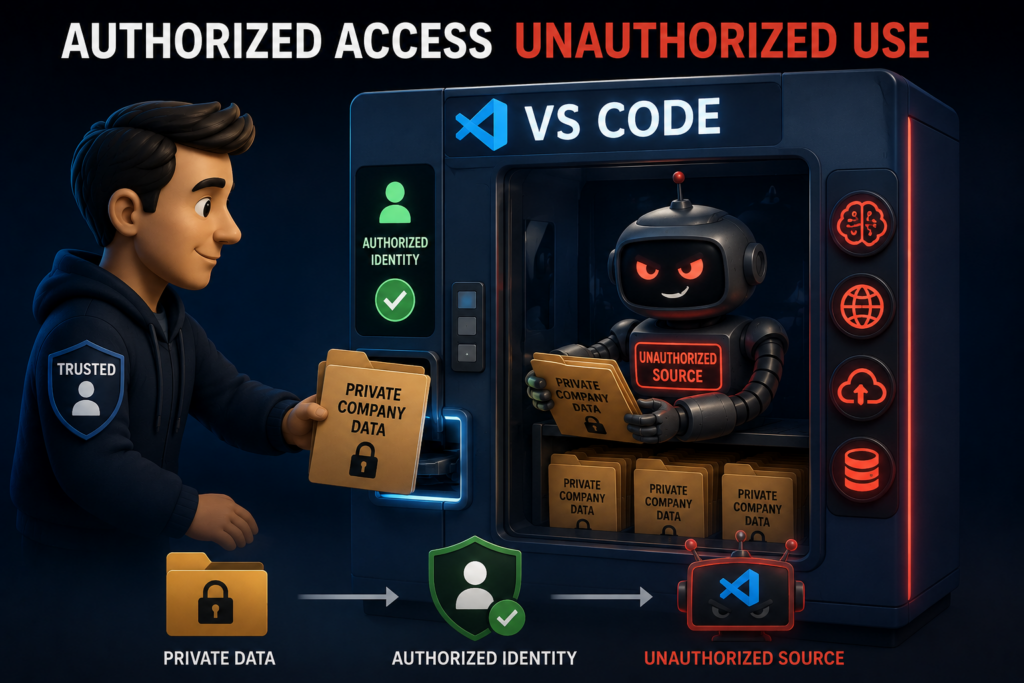
The GitHub Copilot problem
Enterprise organizations can improve governance around AI-assisted development by using services like GitHub Enterprise and Copilot Enterprise. These platforms provide significantly more control than unmanaged personal AI tooling by allowing organizations to apply enterprise-managed identities, privacy controls, extension governance, and centralized policy.
The challenge is that VS Code itself is an extremely flexible orchestration platform. A user on a managed workstation may still sign into VS Code using a personal GitHub account, install third-party AI extensions, connect local models, use external APIs, or connect MCP servers.
At that point, the enterprise may have secured the workstation and authentication process while losing visibility into the actual AI processing boundary.
The workflows themselves are often beneficial. AI-assisted investigation tooling can improve incident response, summarization, enrichment, automation development, and hunting capabilities. The concern is whether enterprise telemetry is ultimately being processed or stored in destinations that were never formally approved to handle that information.
Automated activity is detectable based on predictable patterns
One advantage organizations still have is that automated systems tend to create reasonably predictable operational patterns.
Automated or AI-assisted workflows often operate:
- At a scale beyond normal user behavior
- At unusually high speed
- With repetitive query structures
- On predictable schedules or intervals
- During unusual hours
That creates opportunities for detection.
Large-scale repetitive KQL patterns, continuous enrichment activity, rapid summarization loops, or persistent automated queries all become potential indicators of automation-driven workflows.
Organizations following privileged access best practices should also maintain separation between standard user accounts and privileged administrative accounts. Administrative automation activity occurring under a standard user identity may itself become a meaningful signal.
Building a realistic detection model
Organizations may not have the ability to fully control what an authorized administrator, agent identity, or service principal does with data once retrieval has completed successfully.
What organizations can do is identify and catalog automated workflow operations under administrative identities and establish a baseline of known and authorized behavior.
Instead of trying to fully control every downstream use of telemetry, organizations can focus on:
- Identifying known automation paths
- Cataloging approved workflows
- Baselining expected behavior
- Monitoring for newly observed automation patterns
- Reviewing newly discovered workflows
The goal becomes operational visibility and governance.
Practically speaking, this means leveraging multiple telemetry sources together.
Entra sign-in logs can help monitor delegated administrative activity, OAuth grants, service principals, and agent identities.
LAQueryLogs and API telemetry can help identify repetitive query behavior or high-frequency automated operations.
Defender for Cloud Apps can help identify situations where administrative identities are associated with unusually high interaction volumes with public LLMs or external cloud platforms from managed systems.
Defender for Endpoint telemetry can provide visibility into VS Code usage, local tooling, outbound connections, obscure destinations, and device-level activity.
Organizations may also choose to govern which systems are allowed to host development or orchestration tooling in the first place.
The objective is not necessarily to classify activity as malicious.
The objective is to identify: administrative identities or autonomous systems performing previously unknown or unauthorized automation activity against enterprise telemetry.
The enterprise controls that still matter
Even though organizations probably cannot fully control how authorized identities use data after retrieval, there are still several important controls that improve governance and visibility.
Identity separation remains one of the most important. Administrative identities should ideally remain separate from productivity identities. If an administrative identity becomes associated with unusually high interaction volume to public LLMs, external data stores, or AI-driven web applications, that should stand out operationally.
Conditional Access also remains critical. Even if organizations cannot fully govern downstream data handling, they can still ensure that authorized administrative activity is occurring only from managed, monitored, compliant systems.
In Microsoft-centric environments, organizations can use Defender for Endpoint, Defender for Cloud Apps, Purview DLP, WDAC, AppLocker, extension governance, and browser controls to improve visibility into suspicious tooling and data movement activity.
Final thoughts
The traditional security question:
“Who accessed the data?”
is no longer sufficient.
Now we also need to ask:
“What systems participated in processing the data after access occurred?”
That includes AI copilots, MCP servers, agents, IDE extensions, APIs, automation frameworks, local models, and external LLMs.
Time permitting, I may circle back and put together some example queries, detection approaches, or even a workbook that could help identify some of the operational patterns discussed here. For now, the goal was simply to frame the governance problem itself and discuss why this type of activity may become increasingly important for security teams to understand and monitor.
Because the future SOC analyst may not be working alone anymore. They may already be operating alongside autonomous investigative systems running quietly inside the same authenticated session.