The phrase “AI Security” is becoming increasingly difficult to define because the risks change dramatically depending on how organizations interact with AI. Sometimes employees are simply using public AI services to summarize documents or generate content. Sometimes organizations deploy enterprise copilots grounded on internal data. Increasingly, organizations are building AI workflows and agents capable of interacting with APIs, retrieving information, processing content, and taking actions across business systems.

Back in March, I wrote about securing public, enterprise, and privately hosted LLMs from a broader architectural perspective. Revisiting the topic now, I wanted to approach it from a different angle: how the security conversation changes depending on how AI is actually being used inside the organization.
Each step changes the security footprint.
The security concerns associated with using ChatGPT in a browser are very different from the concerns associated with hosting a customer-facing AI assistant, grounding enterprise AI on internal documents, or deploying autonomous agents capable of interacting with production systems. AI security is not one isolated discipline. It is a shifting combination of data governance, application security, identity, operational monitoring, trust management, and safety controls depending on where and how AI is operating.
While this discussion references Microsoft-centric controls and platforms because those are the systems I work with most frequently, the underlying concepts apply broadly across the industry. Whether organizations use Microsoft, Google, OpenAI, Anthropic, AWS, Databricks, or internally developed AI platforms, the core challenge remains the same: understanding how AI changes trust boundaries, automation, data exposure, and operational risk.
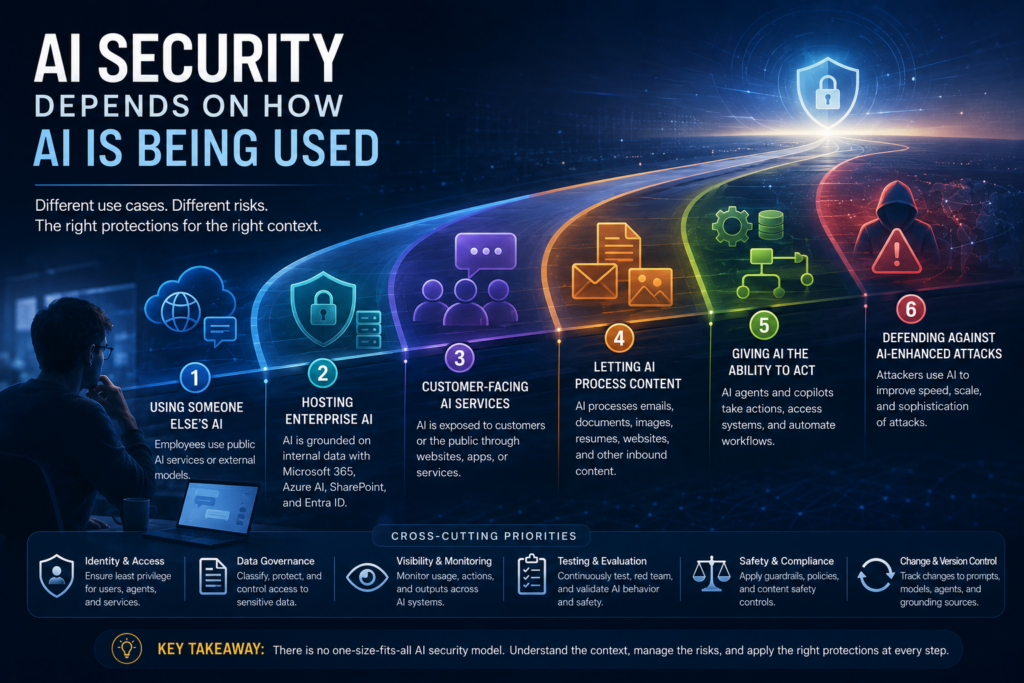
Using Someone Else’s AI
For many organizations, AI adoption begins very simply. Employees open ChatGPT, Claude, Gemini, or another public AI service and start experimenting. They summarize meetings, rewrite emails, analyze spreadsheets, generate code, or brainstorm ideas.
At this stage, the primary concern is usually oversharing.
The AI platform itself may not be compromised or malicious at all. The problem is that employees often paste sensitive information into systems operating outside the organization’s direct control. Internal documents, source code, customer information, legal discussions, financial projections, or security data can quickly leave governed environments through what feels like a harmless conversation.
This is why the first phase of AI security often looks very similar to traditional data loss prevention and insider risk management. In Microsoft environments, tools like Microsoft Purview, Endpoint DLP, and Defender for Cloud Apps help organizations identify when sensitive information is being shared with external AI services or when unsanctioned AI platforms begin appearing inside the environment.
The boundaries also become less clear as organizations begin connecting external AI systems directly to internal resources through APIs, plugins, MCP servers, browser automation, or delegated identity access. In these scenarios, organizations may intentionally grant externally hosted AI platforms access to internal documents, emails, calendars, security data, or business systems in order to improve productivity and automation.
This creates a very different trust model from simply pasting information into a chatbot manually. The concern is no longer only what a user shares during a conversation, but what an externally hosted AI system may continuously access, retrieve, summarize, or process over time. As AI ecosystems become increasingly interconnected, organizations will need stronger governance around delegated AI access, connected tools, plugin trust, and external orchestration platforms.
The challenge is that these interactions feel helpful and productivity-focused rather than obviously risky. Employees are usually trying to work faster, not bypass security controls.
Hosting Enterprise AI
The conversation changes once organizations begin hosting or deploying enterprise AI systems internally. Platforms like Microsoft 365 Copilot, Azure AI Foundry, and grounded enterprise copilots are intentionally connected to organizational documents, emails, meetings, chats, and business systems.
At this point, the concern is no longer just what users share with AI. The concern becomes what the AI itself is allowed to access.
One of the biggest misconceptions around enterprise AI is that the AI creates entirely new exposure. In many cases, it simply exposes governance problems that already existed. Overshared SharePoint sites, unmanaged sensitive files, weak data classification, or excessive permissions become dramatically more visible once AI systems can rapidly aggregate and summarize information conversationally.
A user may suddenly retrieve sensitive information through natural language that technically existed within their permissions all along but would never realistically have been discovered manually.
This is where governance becomes foundational to AI security. In Microsoft environments, tools like Microsoft Purview, sensitivity labels, SharePoint governance, and Microsoft Graph permission boundaries become increasingly important because the AI inherits the organization’s existing trust model, for better or worse.
Organizations also have to think carefully about reliability and business risk. Hallucinations, misleading recommendations, inaccurate summaries, or unsafe guidance may create operational or legal concerns even inside internal employee-facing systems. An internal HR assistant, for example, could still create liability if it produces discriminatory recommendations or encourages harmful actions.
Customer-Facing AI Services
The risk profile expands significantly once organizations expose AI systems to customers or the public.
Public-facing AI systems may interact with thousands or millions of users generating unpredictable combinations of prompts, conversations, edge cases, and interaction patterns. Some users will intentionally try to manipulate or abuse the service, but the larger challenge is often scale itself.
Even well-intentioned users may unintentionally discover conversational paths that produce undesirable behavior. In many ways, this begins to resemble a form of accidental social engineering where the AI is gradually influenced through context, conversational framing, or prompt sequencing rather than through a single obviously malicious request.
This is where concepts like jailbreaks, abuse testing, safety filtering, and reputation protection become critically important.
A customer-facing AI assistant that produces offensive responses, unsafe medical advice, harmful recommendations, discriminatory output, or instructions encouraging self-harm can quickly become a legal, regulatory, and public relations problem. Even if the underlying AI model behaves correctly most of the time, the small percentage of unsafe or manipulated responses may still create enormous reputational damage once exposed publicly.
These same concerns can still exist internally as well. Insider misuse, unsafe recommendations, or harmful outputs can still create legal or operational issues even inside employee-facing AI systems. The difference is that public-facing systems dramatically expand the trust boundary and expose the AI directly to internet-scale interaction patterns.
This is one reason vendors like Microsoft have invested heavily in Responsible AI tooling within Azure AI Foundry and Copilot Studio. Content filtering, abuse detection, automated red teaming, safety evaluations, and configurable guardrails all help organizations test and monitor AI systems before exposing them broadly to users.
The challenge is not simply whether the AI works. The challenge is ensuring the AI continues behaving safely and predictably across an enormous range of unpredictable interactions.
Letting AI Process Content
As organizations operationalize AI further, many systems begin processing content automatically. Emails, resumes, PDFs, uploaded documents, websites, screenshots, and other inbound content increasingly become inputs into AI workflows.
This creates a very different type of security challenge.
Now the concern is not necessarily what users type into AI, but what instructions may exist inside the content the AI consumes. A malicious resume might attempt to manipulate how an AI hiring assistant scores applicants. A crafted PDF or webpage could attempt to override instructions, expose information, alter prioritization logic, or influence how the AI interprets requests and policies. An image submitted into an automated financial workflow might attempt to manipulate how an AI interprets the contents of a check or invoice, potentially influencing extracted values, approvals, or downstream automation.
The concern is not always that the document itself is malicious in a traditional malware sense. The concern is that instructions embedded within otherwise legitimate content may intentionally attempt to manipulate how the AI behaves.
The risk is that the AI may interpret hidden instructions or contextual manipulation not simply as data, but as operational guidance.
This is where concepts like prompt injection and poisoning become genuinely important. These risks are often misunderstood because they are usually far more relevant for AI systems organizations host themselves than for casual use of public chatbots. An AI system that only answers questions creates one level of risk. An AI system that processes external content while interacting with tools, workflows, or enterprise data creates another entirely.
In Microsoft environments, tools like Defender for Office 365, Safe Attachments, Safe Links, and Defender for Endpoint become increasingly important because AI systems effectively become another consumer of enterprise content. The same malicious document that targets a human user may eventually attempt to target an AI-driven workflow as well.
Giving AI the Ability to Act
The security model changes again once AI moves beyond generating responses and begins taking actions.
Agents, copilots, and orchestration platforms can now retrieve files, interact with APIs, automate workflows, coordinate tasks, send communications, and interact with business systems. At this point, AI starts resembling a privileged automation platform rather than a traditional application.
The primary concern becomes controlling what the AI is allowed to do and tracking what actions it performs.
Organizations increasingly need to distinguish between actions performed by users, applications, and autonomous agents. If an AI agent behaves unexpectedly, retrieves sensitive data, or performs unsafe actions, organizations need visibility into that activity just as they would for a privileged administrator or automation platform.
This is where Microsoft’s broader Agent 365 vision starts becoming important. As organizations deploy increasing numbers of agents and autonomous workflows, they will need governance models specifically designed for digital workers. Agent identities, scoped permissions, Managed Identity, approval workflows, API governance, and operational monitoring all become increasingly important once AI systems begin acting inside the environment rather than simply responding to prompts.
Instruction management also becomes critically important. Small changes to prompts, grounding instructions, retrieval sources, models, or connected tools can dramatically alter how an AI behaves. Organizations increasingly need versioning, rollback capability, approval workflows, and change tracking not only for application code, but also for prompts, agent instructions, and grounding configurations.
Traditional software testing alone is no longer sufficient. Organizations increasingly need evaluation frameworks capable of retesting AI behavior whenever models, instructions, grounding data, orchestration logic, or connected tools change.
Testing AI systems also becomes more complicated as models become increasingly adaptive over time. Long-term memory, evolving grounding data, changing orchestration logic, updated models, and continuously connected data sources may all gradually influence system behavior.
Organizations may eventually require continuous evaluation pipelines rather than one-time testing exercises. Red teaming, behavioral regression testing, safety evaluations, and automated validation may need to operate continuously in order to identify when an AI system begins behaving differently than expected.
Traditional software behaves largely the same way until code changes occur. AI systems increasingly blur that boundary because behavior may shift gradually through changing context, memory, data, or interaction patterns even when the surrounding application remains relatively unchanged.
Defending Against AI-Enhanced Attacks
At the same time organizations are adopting AI internally, attackers are adopting it externally.
Much of the public discussion around AI-powered attacks becomes overly dramatic, but the practical reality is still concerning. AI lowers skill barriers, increases attack speed, improves phishing realism, enhances social engineering, and allows attackers to produce more convincing malware, scripts, and fraudulent content at scale.
Deepfakes, polymorphic phishing campaigns, AI-assisted vulnerability research, and low-code malware development all become easier when attackers have access to capable AI tooling.
This does not necessarily mean AI invented entirely new categories of attacks overnight. It means many existing attacks become faster, cheaper, and more scalable.
Defensive platforms are evolving in parallel. In Microsoft environments, services like Defender XDR, Defender for Office 365, Defender Threat Intelligence, Sentinel, and AI-assisted analytics increasingly rely on automation and machine learning themselves to identify abnormal behavior, suspicious communications, and rapidly evolving attack patterns.
Both attackers and defenders are becoming increasingly automated.
AI Security Is Really About Trust Boundaries
By the end of the conversation, the phrase “AI Security” starts to feel almost misleading because there is no single AI risk model.
If employees are using someone else’s AI, the primary concern is oversharing data.
If organizations host AI internally, governance and data exposure become critical.
If AI processes content, prompt injection and poisoning risks emerge.
If AI can take actions, identity, permissions, monitoring, and operational governance become central concerns.
If organizations expose AI publicly, reputation, safety, abuse prevention, and legal liability become major factors.
And throughout all of this, organizations must still defend against attackers who are becoming increasingly AI-enabled themselves.
The challenge is not that AI replaces existing security disciplines. The challenge is that AI intersects with nearly all of them simultaneously.